Сначала миром NLP правили рекуррентные сети (RNN, LSTM), потом появился механизм внимания — attention, который, применительно к рекуррентным сетям, давал огромный буст на всех тестах. Далее ребята из гугла предположили, что attention настолько крутой, что справится и без RNN — так появился первый трансформер в статье Attention Is All You Need. Тот трансформер состоял из энкодера и декодера и умел только переводить текст, но делал это очень круто.
Потом произошёл великий раскол: в OpenAI решили, что от трансформера надо оставить только декодер, а Google решил сконцентрироваться на энкодере. Так появились первые GPT и BERT, породив целый зоопарк себе подобных моделей.
Так что же такое GPT?
Короткий ответ — это нейронная сеть для генерации (продолжения) текста. Если чуть подробнее и сложнее, то это — языковая модель, основанная на архитектуре трансформер и обученная в self-supervised режиме на куче текстовых данных.
Оригинальные статьи про три поколения GPT:
- Improving Language Understanding by Generative Pre-Training (2018)
- Language Models are Unsupervised Multitask Learners (2019)
- Language Models are Few-Shot Learners (2020)
Hugging Face — лучшая библиотека для работы с трансформерами
Для работы с gpt что это нам нужно будет скачать предобученную модель. Лучший выбор для работы с трансформерами — это библиотеки от Hugging Face: transformers, tokenizers, datasets — самые любимые библиотеки любого нлпшника. Все они разработаны стартапом Hugging Face, который стремится стандартизировать архитектурные решения для работы с transformer-based моделями. Также они выполняют функцию своеобразного хаба предобученных весов огромного количества трансформеров.
В данном туториале мы будем работать только с библиотекой transformers и, для наглядности, с русскоязычной моделью ruGPT3 от Сбера.
# Сначала установим библиотеку transformers
!pip install transformers
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Для наглядности будем работать с русскоязычной GPT от Сбера.
# Ниже команды для загрузки и инициализации модели и токенизатора.
model_name_or_path = "sberbank-ai/rugpt3large_based_on_gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_name_or_path)
model = GPT2LMHeadModel.from_pretrained(model_name_or_path).to(DEVICE)Языковое моделирование
Чтобы разобраться, как работает GPT, нужно понять, какую задачу пытается решать эта модель. Языковое моделирование — это предсказание следующего слова (или куска слова) с учётом предыдущего контекста. На картинке пример того, как с задачей языкового моделирования справляется поиск Яндекса.

Для того чтобы «всего лишь» дописывать текст, модель должна очень хорошо понимать его смысл и даже иметь какие-то свои знания о реальном мире. Внутренние знания модели можно попытаться вытащить наружу, модифицируя «левый контекст» текста. Это позволяет решать множество задач: отвечать на вопросы, суммаризировать текст и даже создавать диалоговые системы!
Например, если мы хотим при помощи языковой модели ответить на вопрос «Сколько будет 2+2?», то можно подать на вход модели следующий текст «Вопрос: Сколько будет 2+2? Ответ: … » и самым естественным продолжением такого текста будет именно ответ на вопрос, поэтому хорошая языковая модель допишет «4».
Подбор модификаций текста называется «Prompt Engineering». Такая простая идея позволяет решать практически неограниченное количество задач. Именно поэтому многие считают GPT-3 подобием сильного искусственного интеллекта.
# prompt engineering for QA
text = "Вопрос: 'Сколько будет 2+2?'\nОтвет:"
input_ids = tokenizer.encode(text, return_tensors="pt").to(DEVICE)
out = model.generate(input_ids, do_sample=False)
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
#>>> Вопрос: 'Сколько будет 2+2?'
#>>> Ответ: '2+2=4'Похожим способом можно кратко пересказывать тексты, если в конце дописывать «TL;DR», потому что модель во время обучения запомнила, что после этих символов идёт краткое содержание. А ещё можно сделать переводчик с русского на английский:
# prompt engineering for Translation
text = "По-русски: 'кот', по-английски:"
input_ids = tokenizer.encode(text, return_tensors="pt").to(DEVICE)
out = model.generate(input_ids, do_sample=False)
generated_text = list(map(tokenizer.decode, out))[0]
print(generated_text)
#>>> По-русски: 'кот', по-английски: 'cat'Токенизация
Машинное обучение лучше справляется с числами, чем с текстом, поэтому нам необходима процедура токенизации — преобразование текста в последовательность чисел.
Самый простой способ сделать это — назначить каждому уникальному слову своё число — токен, а затем заменить все слова в тексте на эти числа. Но есть проблема: слов и их форм очень много (миллионы) и поэтому словарь таких слов — чисел получится чересчур большим, а это будет затруднять обучение модели. Можно разбивать текст не на слова, а на отдельные буквы (char-level tokenization), тогда в словаре будет всего несколько десятков токенов, НО в таком случае уже сам текст после токенизации будет слишком длинным, а это тоже затрудняет обучение.
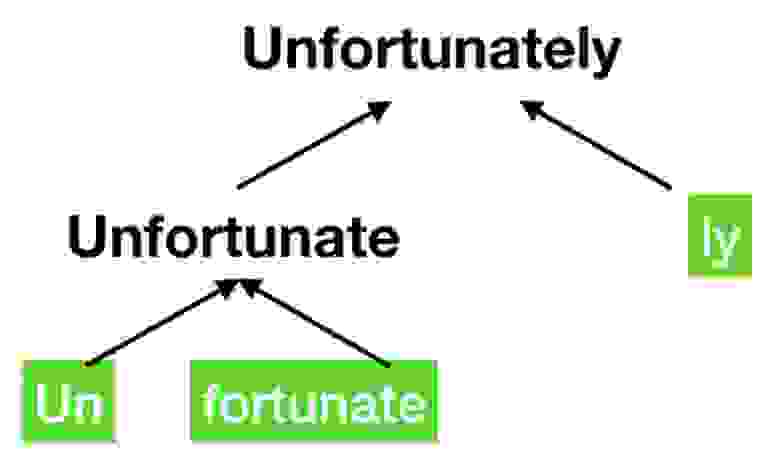
Обычно предпочтительнее выбрать что-то среднее, например, можно разбивать слова на наиболее общие части и представлять их полные версии как комбинации этих кусков (см. картинку). Такой способ токенизации называется BPE (Byte Pair Encoding). Но даже это иногда не самый оптимальный выбор. Чтобы сжать словарь ещё сильнее для обучения GPT OpenAI использовали byte-level BPE токенизацию. Эта модификация BPE работает не с текстом, а напрямую с его байтовым представлением. Использование такого трюка позволило сжать словарь до всего-лишь ~50k токенов при том, что с его помощью всё ещё можно выразить любое слово на любом языке мира (и даже эмодзи).